Obtendo um Dataset diretamente do GitHub com Python
Por que fazer o download do repositório inteiro para pegar o arquivo CSV ou XLSX desejado?
Os datasets são de grande importância, visto que carregam um conjunto de informações a serem processadas, visando visualizá-las para tirar conclusões, ou construir modelos computacionais capazes de prover soluções, prever comportamentos e/ou observar padrões. Por esse motivo, esses arquivos, que podem ser encontrados, comumente, nos formatos CSV ou XLSX, por exemplo, são bastante utilizados pelo cientista de dados. Se você curte essa área, hoje vai uma dica super legal para você.
Existem diversos repositórios do GitHub que fornecem excelentes conjuntos de datasets. Como exemplo, podemos citar o repositório do Centro de Ciência e Engenharia de Sistemas (CSSE) da Universidade Johns Hopkins, que contém dados da COVID-19 no mundo inteiro e que é atualizado diariamente (você pode acessar esse repositório nesse link). Um dataset específico desse repositório foi, inclusive, analisado em uma série de três vídeos do meu canal.
Suponhamos que você deseje utilizar um dataset do repositório mencionado anteriormente; como você faria?
Opção 1: Fazer o download do repositório inteiro para o seu computador e pegar o dataset desejado. Mas, e horas depois, quando o repositório for atualizado… Você faria o mesmo processo novamente?
Opção 2: Clonar o projeto usando o Git e, todos os dias, fazer uma atualização desse repositório. Essa opção parece melhor, mas ainda não é a ideal.
Opção 3: Utilizar um código em Python capaz de pegar o link do arquivo desejado e fazer o download automaticamente para o seu computador, de modo que, a cada execução é baixada a versão mais recente do mesmo. Essa parece ser a melhor opção e a seguir eu irei te ensinar como fazer isso.
Passo 1: Importar as bibliotecas
Antes de tudo, é necessário importar as bibliotecas. Vamos utilizar o Pandas para fazer a leitura do arquivo CSV que iremos baixar do GitHub e, também, vamos utilizar uma função do submódulo request da biblioteca urllib (que é nativa do Python, ou seja, não precisa instalar nada) para fazer o download do arquivo pelo seu próprio link.
import pandas as pd from urllib.request import urlretrieve
Passo 2: Obter o link para o download
Para obter o link para o download do arquivo, você precisa abrir o arquivo desejado no GitHub (vamos utilizar o arquivo desse link, para exemplificar) e, em seguida, clicar no botão Raw (o primeiro botão do canto direito do cabeçalho do arquivo, como você pode ver na figura abaixo).
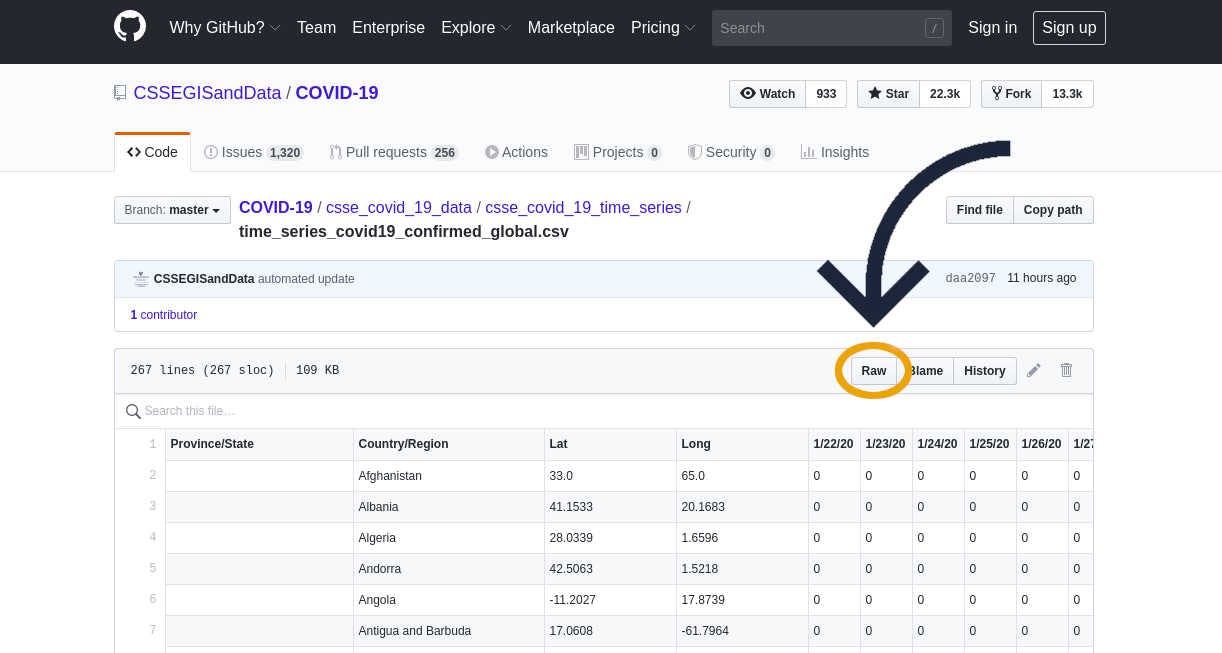
Fazendo isso, será carregada uma página que contém apenas o conjunto de dados, sem formatação (ver figura abaixo). Agora você deve copiar o link dessa página para utilizá-lo no próximo passo.

Passo 3: Obter no arquivo utilizando o link
Agora, com o link copiado, você pode salvá-lo em uma variável url, por exemplo:
url = ‘https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv’
Agora, utilize a função urlretrieve para obter o arquivo desejado. Observe que essa função exige, pelo menos, dois parâmetros. O primeiro é o link do arquivo que você deseja baixar, e o segundo é o diretório e o nome do arquivo. Nesse caso, estamos salvando no mesmo diretório do código, com o nome global_cases_covid19.csv, visto que se trata de um arquivo CSV.
urlretrieve(url, 'datasets/global_cases_covid19.csv')
Após a execução desta linha, você já pode conferir que o arquivo já vai aparecer no seu computador.
Passo 4: Carregar o arquivo com o pandas
Finalmente, você pode carregar o seu arquivo utilizando a função read_csv do Pandas:
df_covid = pd.read_csv('global_cases_covid19.csv')Pronto! Gostou desse post? Então, não deixa de me seguir no Instagram ou no Canal do Telegram para acompanhar todas as novidades do Blog e do canal do YouTube. Um abraço e até a próxima!