Como importar tabelas de sites com o Pandas?
Obtendo dados contidos em tabelas de sites por meio de duas funções do Pandas
Quando trabalhamos com análise de dados, tudo que a gente mais deseja são os dados. Temos que admitir isso. Mas a verdade é que, muitas vezes, esses dados são tão fáceis de serem obtidos. Felizmente, a biblioteca do Pandas nos dá um conjunto bem amplo de funções que nos permitem obter esses dados dos mais diversos tipos de arquivos, tais como CSV, XLSX, JSON, dentre outros.
No entanto, um dos que talvez você ainda não conheça é aquele que te permite ler dados de uma página HTML, mais especificamente as tabelas que estão disponíveis naquele site. É isso mesmo! Muitas vezes você pode ter se deparado com uma tabela em algum site que encheu os seus olhos pelas informações que estavam contidas nela. É possível até que você tenha deseja obter aqueles dados para fazer um processamento, levantar um gráficos ou até aplicar um algoritmo de Machine Learning para encontrar algum padrão; mas pensou que teria que fazer algo mirabolante ou trabalhoso para jogar aquilo em um DataFrame.
Por isso, o objetivo desse artigo é te apresentar duas formas super simples que vão te permitir jogar dados de tabelas de sites diretamente em um DataFrame. Vamos nessa!
Bibliotecas Importantes
Primeiramente, claro, você precisa ter a biblioteca do Pandas instalada. Mas, além dela, é importante que você instale duas biblioteca: lxml e bs4. Embora você não precise importá-las no seu algoritmo, elas são requeridas quando formos utilizar uma das funções que eu irei te apresentar.
Para instalar essa biblioteca via Pip no Windows, você deve abrir o cmd e digitar o comando: pip install lxml bs4. Já no Linux, você deve abrir o Terminal e digitar o comando: pip3 install lxml bs4. Pronto! Você já tem tudo que é necessário. Vamos para a primeira forma!
1. Utilizando a função read_html
Pois é… Já existe uma função do Pandas, chamada read_hmtl, que te permite ler o conteúdo de uma página HTML. Para ser mais específico, ele vai “varrer” o código HTML inteiro da página em busca de tabelas. Todas as tabelas que ele encontrar serão adicionadas a uma lista (list). Ou seja, o retorno dessa função é uma lista de DataFrames, em que cada DataFrame contém uma tabela do site.
Isso significa que, mesmo que o site contenha apenas uma tabela, o retorno será uma lista com apenas um elemento: a única tabela da página, que já estará armazenada em um DataFrame. E se não houver tabelas na página? Nesse caso, o programa retornará uma exceção para você: ValueError: No tables found.
Mas, como você deve utilizar essa função. É super simples! O único parâmetro que você precisa especificar é o url da página que contém a tabela que você deseja obter. Vejamos o exemplo abaixo:
import pandas as pd
df_list = pd.read_html('https://www.fdic.gov/resources/resolutions/bank-failures/failed-bank-list/')Observe que df_list é a variável que receberá o retorno da função read_html. Esse retorno será uma lista de DataFrames. A função read_html contém apenas uma string que consiste na url da página. Essa página (você pode clicar aqui para acessá-la) contém uma tabela com algumas informações sobre bancos que já faliram. Ao executar esse linha de código, e imprimir o conteúdo da variável df_list, você obterá o resultado abaixo:
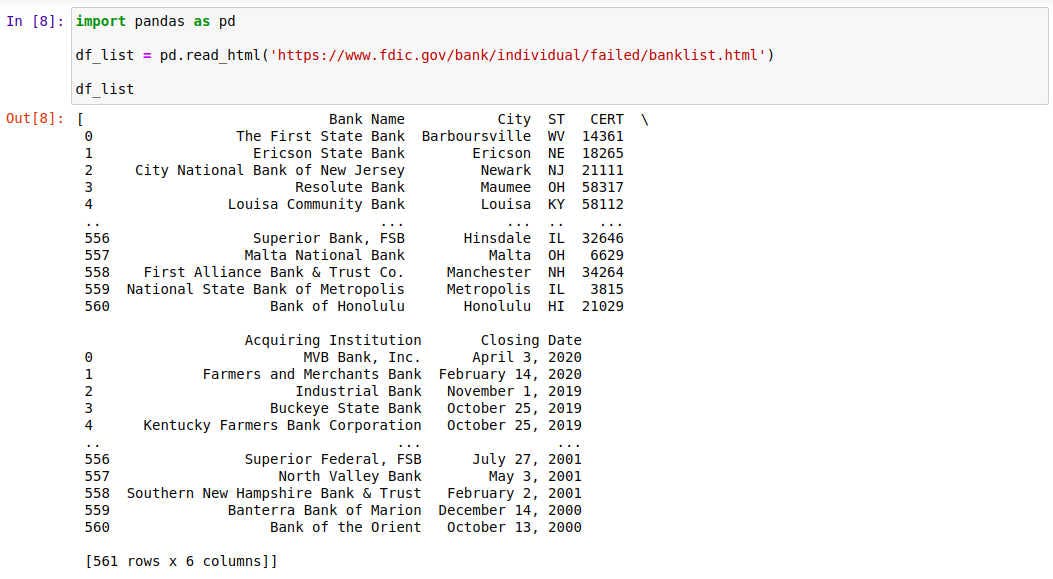
Note que o conteúdo dessa variável é uma lista, que possui apenas um elemento, inclusive (experimente dar o comando len(df_list) para comprovar isso). Portanto, imprimindo a posição 0 dessa lista, chegaremos ao DataFrame:
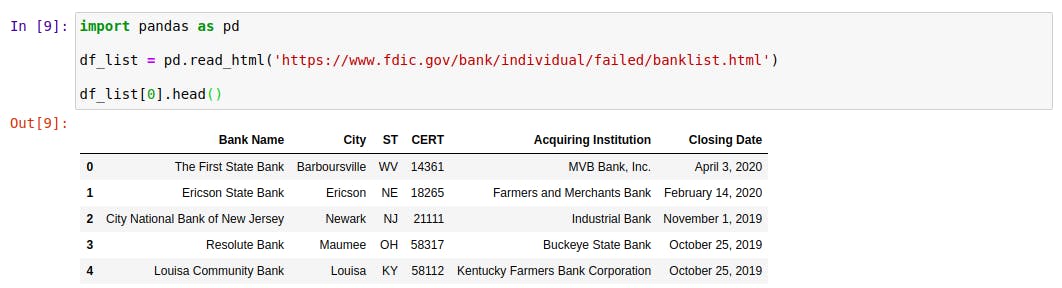
Excelente! O DataFrame contém exatamente o mesmo que estava presente na tabela do site. Agora, vamos testar para uma notícia do G1, por exemplo (você pode acessá-la nesse link):
import pandas as pd
df_list = pd.read_html('https://g1.globo.com/bemestar/coronavirus/noticia/2020/05/26/casos-de-coronavirus-e-numero-de-mortes-no-brasil-em-26-de-maio.ghtml')Se você imprimir o tamanho de df_list (len(df_list)), observará que o resultado será 2, ou seja, essa página possui duas tabelas e ambas estão contidas na lista. Agora, ao imprimir a primeira tabela (df_list[0]), temos:

Note que, dessa vez, o cabeçalho da tabela do site não se tornou o label das colunas do DataFrame. Por que isso aconteceu? O fato é que a tabela do site que utilizamos no primeiro exemplo tem uma tag thead, que define o cabeçalho de uma tabela no HTML. A função read_html utiliza essa tag para saber quais serão os labels atribuídos às colunas do DataFrame (como foi o caso do primeiro exemplo). Quando essa tag não está presente na tabela (o caso do segundo exemplo), ela criará um label automático (0, 1, 2, …).
2. Um método alternativo: a função read_clipboard
Já ouviu falar nessa função? Ela é capaz de capturar o conteúdo que está na sua área de transferência (ou seja, aquilo que você copiou usando o famoso Ctrl+C) e salvar em um DataFrame. E por que essa função é importante?
O que acontece é que a função read_html não funciona em alguns sites; se você tentar utilizá-la, obterá um erro do tipo HTTPError: HTTP Error 403: Forbidden. Nesse caso, você pode copiar a tabela dentro do próprio navegador e, em seguida, utilizar a função read_clipboard. Pronto! Dessa forma, você vai ter a tabela salva em um DataFrame!
Gostou desse post? Então, não deixa de me seguir no Instagram ou no Canal do Telegram para acompanhar todas as novidades do Blog e do canal do YouTube. Um abraço e até a próxima!